目的 对于 Java 开发者来说,我认为最好了解下 Kotlin,它确实提升了开发效率,有非常多的优点。这篇文章将介绍 Kotlin 的现状和一些优秀特性,并和 Java 做对比。希望大家能对这个语言感兴趣,平常有一些小玩意的话,也可以用 Kotlin 尝试一下。
什么是 Kotlin? Kotlin 是一种开源静态类型编程语言,面向 JVM、Android、JavaScript 和 Native。它由 JetBrains 开发 。该项目始于 2010 年,第一个官方 1.0 版本于 2016 年 2 月发布。
它能做什么?
Android 开发,2017 年谷歌宣布 Kotlin 为开发 Android 的首选语言。
服务端开发,与 JVM 100% 兼容,可以使用现有的框架。Spring 也在加快对 Kotlin 的支持,https://start.spring.io/ 上 Language 可选 Kotlin,且部分源代码已使用 Kotlin 改写,博客中还有非常多相关文章。
Web开发,在针对 JavaScript 时,Kotlin 会转译为 ES5.1 并生成与包括 AMD 和 CommonJS 在内的模块系统兼容的代码。
原生开发,Kotlin/Native 是 Kotlin 项目的一部分,它将 Kotlin 编译为无需 VM 即可运行的特定于平台的代码。(目前处于测试阶段)
发展
JetBrains 于 2011 年推出 Kotlin
2016 年发布第一个稳定版本 Kotlin 1.0
2017 年 Google 宣布 Kotlin 正式成为Android 的开发首选语言
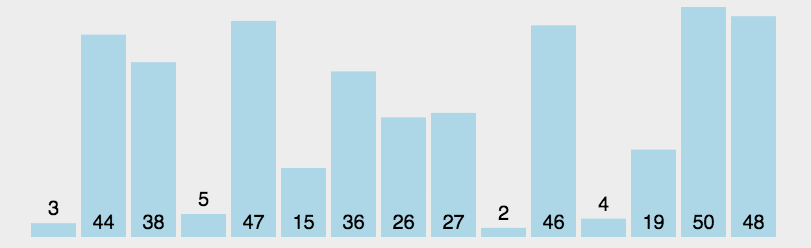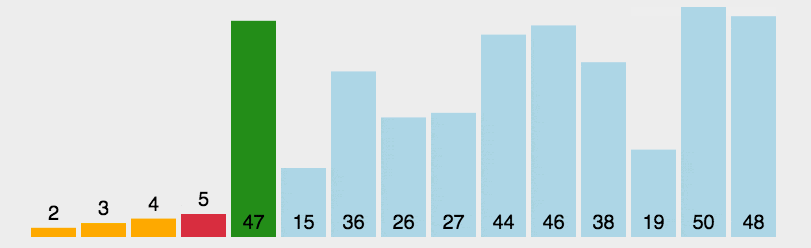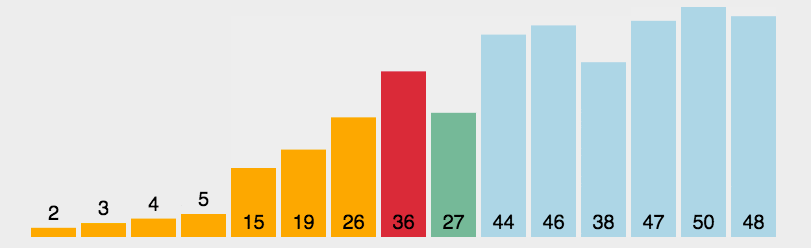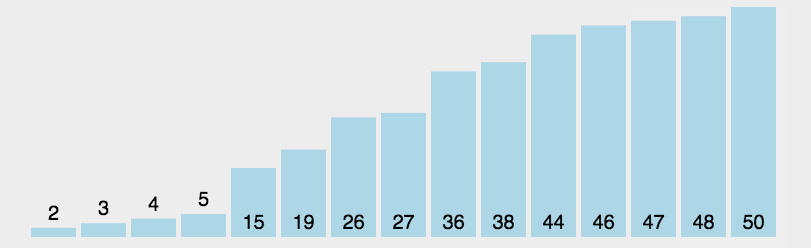
2021 开发者生态系统现状
兼容性 Kotlin 与 Java 100% 兼容,可以使用所有的现有框架,例如 Spring、Vert.x。两种语言也可互操作,可以轻松地从 Java 调用 Kotlin 代码或者从 Kotlin 调用 Java 代码。IDE 中还内置了一个自动化的 Java 到 Kotlin 的转换器,可简化现有代码的迁移。但生产中,还是不太建议这样操作,一是转换的代码可读性可能不符合你的期望,二是如果类特备复杂,则影响范围较大有一定风险。可根据类的复杂度,自行抉择是否转换。
(有一句俗话,Java 最好的第三方库是 Kotlin。
优势 Kotlin 更简洁, 根据官方的数据,**代码行数约减少了 40%**。
其次,空安全 ,程序不再容易 NPE 的影响。
其他高级特性,如智能转换、高阶函数、扩展函数等等,提供了编写富有表现力的代码的能力。
难学吗? Kotlin 的灵感来自 Java、C#、JavaScript、Scala 和 Groovy 等语言,在下面的特性介绍中可以看到很多其他语言的影子。它的基础语法非常易于学习,可以在几天内轻松上手、阅读和编写 Kotlin。 但如果想要学习更多高级功能可能需要更长的时间,但总体而言,它不是一门复杂的语言。
由于 Kotlin 也基于 JVM,可以反编译字节码,再将其转为 Java,这是学习 Kotlin 一种较好的方式,能快速理解。
特性 空安全 在平常的开发和自测过程中,遇见最多的异常可能就是 NPE 了。Kotlin 吸取了 C# 的做法,从源头上抓起,区分了可空引用和不可空引用。空引用:十亿美元的错误
例如,常规的 String 类型的变量就不能容纳 null,在变量类型后面加上一个问号,才表明这个变量可以为 null。如果尝试将一个可空类型的变量直接赋值给一个不可空类型变量,或者访问一个可空类型变量的属性,在编译编译阶段,都会报错。
在语法层面强制 null,这点从实际工程角度来说是非常有利的。
1 2 3 4 5 6 // Kotlin var output: String output = null // Compilation error val name: String? = null // Nullable type println(name.length()) // Compilation error
如果一个变量 b 可能是空,那该如何访问它的属性?
判断 null 这和 Java 几乎差不多。先判断是否为 null,不为 null 再操作
1 2 // Kotlin val l = if (b != null) b.length else -1
安全的调用 ?. 或者可以使用安全调用操作符 ?. :
1 2 3 4 5 // Kotlin val a = "Kotlin" val b: String? = null println(b?.length) println(a?.length) // 无需安全调用
如果 b 非空,就返回 b.length, 否则返回 null, b?.length 表达式的类型是 Int?
在这个例子中,安全调用看起来很普通,但在链式调用中能简化非常多代码。例如,在业务中经常会获取某个嵌套很深的属性,在 Java 中,就是要做逐层判断,或者使用 Java8 新增的 Optional 类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 // Java 逐层判断 if(a != null) { if (a.b != null) { if (a.b.c != null) { // 在此处访问 d 属性 ans = a.b.c.d; } } } // Java 使用 Optional,但还是有不适感 Optional.ofNullable(a) .map(it -> it.b) .map(it -> it.c) .map(it -> it.d) .get() // Kotlin 安全操作符 一行即可 val d = a?.b?.c?.d
Elvis 操作符 ?: 当我们有一个可空的引用 b 时,我们可以说“如果 b 非空,我使用它;否则使用某个非空的值”:
1 2 3 4 5 6 7 8 9 // Java if(b != null) { return b.length; } else { return -1; } // Kotlin return b?.length ?: -1
如果左侧的 b?.length 不为空,那就返回,否则就返回右侧的表达式。仅当左侧为空时,才会对右侧进行运算。
由于 throw 和 return 在 Kotlin 中都是表达式,所以非常方便用于检测一些入参或者快速返回:
1 2 3 4 5 6 // Kotlin fun foo(node: Node): String? { val parent = node.getParent() ?: return null val name = node.getName() ?: throw IllegalArgumentException("name expected") // …… }
!! 操作符 这是不优雅的操作,这是非空断言运算符,可以将任何值转换非空类型,如果为空,则会抛出异常,所以使用该运算符可能会得到一个 NPE
协程 和 Java 相比,协程是 Kotlin 一个新颖的概念,不过协程不是 Kotlin 提出的概念。在网上搜索协程,我们会看到:
Kotlin 官方文档上说「本质上,协程是轻量级的线程」。
很多博客提到「不需要从用户态切换到内核态」、「是协作式的」等等。
协程早在 1958 年就被 Melvin Conway 提出并用用于构建汇编程序,协程是一种编程思想 ,并不局限于特定的语言。
从 Java 开发者的角度去理解 Coroutines 和 Threads 的关系:
我们所有的代码都是跑在线程中,而线程是跑在进程中的。
协程没有直接和操作系统关联,操作系统并不知道协程的存在。但它不是空中阁楼,它也可以跑在线程中,可以是单线程,也可以是多线程。
单线程中的协程总的执行时间并不会比不用协程少。
而 Kotlin 的协程,它本质上只是线程池的包装,封装成一套好用的 API,Java仅仅是没有解决 「写得优雅 」这个问题。
由于 Android 的 UI 主线程不能阻塞,所以所有 IO 等耗时操作都要放在 work 线程中,并使用异步回调的方式来更新UI,导致会有大量的回调地狱。因此协程在 Android 上有非常明显的优势,能用同步的方式写出异步+回调的非人类代码。
而对于服务端来说,虽然也可以再一些阻塞态问题上使用协程,但目前都是同步编程,协程的效益并没有那么明显,如果使用的是异步编程框架,则有质的飞越。
参数默认值 函数参数可以有默认值,当省略相应的参数时使用默认值。否则就需要通过重载方法来实现参数默认值,如果有4个可选参数,则要写 2^4 = 16 个重载方法,而带有这个语法的语言(js、c++、python)会有明显优势。
1 2 3 4 5 6 7 8 // Kotlin fun bar(a:Int, b: String = "hello", c: Int = 0) {} // Java 重载 void bar(int a, String b) { bar(a, b, 0);} void bar(int a) { bar(a, "hello", 0);} void bar(int a, int c) { bar(a, "hello", c);} void bar(int a, String b, int c) {}
命名参数 在工程中,如果一个方法的参数过多,将参数依次对应起来是件比较麻烦的事情,尤其是当所有参数类型都一致的时候,更需要小心。如果对错了,编译能通过,但会出现逻辑错误,此类 bug 可能要排查很久。
而 Kotlin 在函数调用中可以使用命名参数,还可以自由更改它们的列出顺序,如果要使用它们的默认值,可以完全忽略此参数。
1 2 3 4 5 6 7 8 // Java 入参过多,且类型都相似 void bar(int a, int b, int c, int d, int e) {} // Kotlin // 方法定义 fun bar(a: Int, b: Int, c: Int, d: Int, e: Int) {} // 方法调用 bar(c = 3, d = 4, e = 5, a = 1, b = 2)
扩展函数 对于 Java 而言,如果想扩展一个类的新功能需要继承原来的类,或者使用装饰者这样的设计模式。但有的类来自第三方库,无法修改,或者被 final 修饰,这些情况下,Java 将无能为力,只能使用静态方法,将此类的对象传入进去。而 Kotlin 的扩展方法则无任何限制,新增的函数就像原始类本来就有的函数一样,可以用普通的方法调用。(如果查看字节码,会发现其实现就是静态方法,第一个入参为扩展类的对象)
Kotlin 鼓励开发者尽量精简类的定义,一个类只定义框架,工具函数可以通过外部扩展一点点地添加,尽量不改动原有的类,这也是扩展方法的意义,让代码更加简单和整洁。
Java 里的许多工具类,比如 Collections、Arrays、Objects 等等,它们提供了一系列静态方法来充当工具函数,通过参数传入被操作的对象,既不直观又冗长无比,Kotlin 将这些常用的方法都改成了扩展方法,我们可以非常方便的使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 // 自义定一些扩展方法 // 为所有类新增一个 toJson 方法,用于转成 json fun Any.toJson(): String { return gson.toJson(this); } // 还可以为可空类型做扩展,将一些常用的空判断放在扩展方法中 fun Any?.toString(): String { if(this == null) { return "null" } return toString(); } // Kotlin 定义好的一些常用扩展方法 fun String.toInt(): Int = java.lang.Integer.parseInt(this) fun String.toLong(): Long = java.lang.Long.parseLong(this) String.toBigDecimal(): java.math.BigDecimal = java.math.BigDecimal(this) // 还有其他 todouble, tofloat ... // 集合判空 etc... public inline fun <T> Collection<T>?.isNullOrEmpty(): Boolean { return this == null || this.isEmpty() }
扩展是静态解析的,扩展并不能真正的修改他们所扩展的类,通过定义一个扩展方法或熟悉,并没有在类中插入一个新成员,仅仅是通过该类的变量用点表达式去调用这个新函数。
如果一个类定义有一个成员函数和一个扩展函数,且两个函数有完全一样的方法签名,那么只会调用成员函数。
扩展属性 与函数类似,Kotlin 支持扩展属性,当一个类的某些属性可以由该类的其他属性推导出来时,可以使用扩展属性。它只是看着像操作属性,实际上还是方法的访问。
1 2 3 4 5 6 7 8 9 10 11 12 13 open class Student( val stuNo: Int, var name: String, val englishScore: Int, val chineseScore: Int, val mathScore: Int ) // 判断是否通过了考试 var Student.pass: Boolean get() = englishScore >= 60 && chineseScore >= 60 && mathScore >= 60 // 这里的 set 方法单纯演示 set(value) {name = value.toString()}
泛型 Kotlin 泛型与 Java 泛型相似,大都只是名字概念上的变化。这里只讲讲 Kotlin 增强的部分。
由于类型擦除, Java 和 Kotlin 的泛型类型实参都会在编译阶段被擦除,无法知道实际类型,这个问题,在 Java 中的解决方案通常是额外传递一个 Class 类型的参数。但 Kotlin 中存在一个额外手段,即内联函数,此时可以说是【真泛型】。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 // Java public <T> void test(Integer arg) { boolean b = arg instanceof T; // 编译错误 T t = new T(); // 编译错误 T[] array = new T[100]; // 编译错误 T[] array2 = (T[]) new Object[100]; // 警告 } // Kotlio // inline 内联, reified 具象化的 inline fun <reified T> test(arg: Int) { val clazz: Class<T> = T::class.java // 获取泛型的实际类型 val b = arg is T // 判断参数是否是 T 类型 val newInstance = clazz.newInstance() // 创建一个 T 对象 }
应用场景 inline 和 reified 比较有用的一个场景是用在反序列的时候。由于泛型运行时类型擦除的问题,目前用反序列化泛型类时步骤是比较繁琐的,工具类中都需要传入一个 Class 参数,利用 inline 和 reified 我们就可以简化掉这个参数。
1 2 3 4 5 6 val gson = Gson() // 只需一个参数,无需传入类型信息 inline fun <reified T> toBean(json: String): T { return gson.fromJson(json, T::class.java) }
还有一些冷门用法,用于实现不同的返回类型函数重载。无论是 Kotlin 还是 Java,函数签名都是由方法名称和参数构成,返回值不参与,因此无法重载返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 // 需要实现一个 英尺转厘米 的方法,返回值可以是不精确的 int 类型,也可以是 double // 这种方法无法通过编译 fun inchToCm(inch: Double): Int { val cm: Double = inch * 2.54 return cm.toInt() } fun inchToCm(inch: Double): Double { val cm: Double = inch * 2.54 return cm } // 使用 reified,实现不同的返回类型函数重载 inline fun <reified T> inchToCm(inch: Double): T { val cm: Double = inch * 2.54 return when(T::class) { Double::class -> cm as T Int::class -> cm.toInt() as T else -> throw IllegalStateException("Type not supported") } } fun main() { val cm1: Int = inchToCm(12.0) val cm2: Double = inchToCm(12.0) }
实际工程中,一个可能的情景是:有一个方法,需要被多个方法调用,但每个调用方需要的返回值可能是不同的 BO 对象,因此可以对该方法的返回值进行重载,进行类型转换。
原理 如果要是真泛型,则必须是内联函数。内联函数会将代码平铺到所有的调用点,有多少个调用点,就会将泛型方法编译多少次。 Kotlin 通过调用点知道了传入的类型,平铺后,泛型方法就可以知道泛型的类型了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 // 源代码 inline fun <reified T> inlineTest() { println(T::class.java.name) } fun <T> test() { println("aaa") } fun main() { inlineTest<Int>() test<Int>() } // 将其反编译为 Java 代码后再观察 // main 方法并没有直接调用 inlineTest 方法 public final class KTestKt { // $FF: synthetic method public static final void inlineTest() { int $i$f$inlineTest = 0; Intrinsics.reifiedOperationMarker(4, "T"); String var1 = Object.class.getName(); System.out.println(var1); } public static final void test() { String var0 = "aaa"; System.out.println(var0); } public static final void main() { int $i$f$inlineTest = false; String var1 = Integer.class.getName(); // 非调用方法,直接平铺代码并传入调入点的 Integer 类型 System.out.println(var1); test(); // 非内联方法,调用 } // $FF: synthetic method public static void main(String[] var0) { main(); } }
高阶函数与 Lambda 表达式 在 Java 里,如果你有一个 a 方法,需要调用另外一个 b 方法,直接调用即可。而如果想在 a 调用时动态设置 b 方法的参数,就要把参数传给 a,再从 a 的内部把参数传给 b:
1 2 3 4 5 6 // Java int a(int param) { return b(param); } a(1); // 内部调用 b(1) a(2); // 内部调用 b(2)
如果想动态设置的不是方法参数,而是方法本身呢?比如我在 a 的内部有一处对别的方法的调用,这个方法可能是 b,可能是 c,不一定是谁,我只知道,我在这里有一个调用,它的参数类型是 int ,返回值类型也是 int ,而具体在 a 执行的时候内部调用哪个方法,我希望可以动态设置:
1 2 3 4 5 6 // Java int a(??? method) { return method(1); } a(method1); a(method2);
想把方法作为参数传到另一个方法里,这个……可以做到吗?不行,Java 里是不允许把方法作为参数传递的,但有一个历史悠久的变通方案:接口。可以通过接口的方式把方法包装起来:
1 2 3 4 5 6 7 8 9 10 11 12 // Java public interface Wrapper { int method(int param); } int a(Wrapper wrapper) { return wrapper.method(1); } // 在调用外部方法时,传递接口的对象来作为参数: a(wrapper1); a(wrapper2);
而在 Kotlin 里,函数的参数也可以是函数类型 的,这是一种 Java 中不存在的类型,这种类型的对象可以当函数来用,还可以作为函数的参数、返回值,以及赋值给变量。这种「参数或者返回值为函数类型的函数」,在 Kotlin 中就被称为「高阶函数」——Higher-Order Functions。所谓的「高阶」,总给人神秘感,其实概念源自于数学中的高阶函数 ,没有其他特殊功能,唬人的概念罢了。
如下代码,funParam 就是一个函数类型的参数,它接受一个 int 类型的参数,返回类型是 String:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 // Kotlin fun a(funParam: (Int) -> String): String { // somet code ... return funParam(1) } // 定义一个方法,以 lambda 的形式 val bar: (Int) -> String = { param -> param.toString() } // 传进去 a(bar) // 或者直接传进去 a({param -> param.toString()}) // 如果 Lambda 是函数的最后一个参数,你可以把 Lambda 写在括号的外面: a() { param -> param.toString() } // 而如果 Lambda 是函数唯一的参数,你还可以直接把括号去了: a { param -> param.toString() } // 另外,如果这个 Lambda 是单参数的,它的这个参数也省略掉不写,且有默认名字 it a { it.toString() } // 对于一个声明好的函数,不管是你要把它作为参数传递给函数,还是要把它赋值给变量,都得在函数名的左边加上双冒号才行 fun b(param: Int): String { return param.toString() } a(::b)
Kotlin 里「函数可以作为参数」这件事的本质,是函数在 Kotlin 里可以作为对象存在 ——因为只有对象才能被作为参数传递。赋值也是一样道理,只有对象才能被赋值给变量。但函数本身的性质又决定了它没办法被当做一个对象,函数就是函数,没有类型,也不是对象。那怎么办?Kotlin 的选择是,那就创建一个和函数具有相同功能的对象。怎么创建?使用双冒号,这个是底层的逻辑。Kotlin 的 Lambda 本质也是一个函数类型的对象。
Java 的 Lambda 上面我们提到 Java 可以通过接口来传递方法,即:
1 2 3 4 5 6 7 8 // Java Wrapper wrapper1 = new Wrapper() { @Override public int method(int param) { return param * 2; } }; a(wrapper1);
但看看代码,实在是太长了。于是,Java 从 8 开始引入了对 Lambda 的支持,对于单抽象方法的接口——简称 SAM 接口,Single Abstract Method 接口——对于这类接口,Java 8 允许你用 Lambda 表达式来创建匿名类对象,但它本质上还是在创建一个匿名类对象,它没有属性自己的类型,必须要使用一个接口来接收 Lambda。它只是一种简化写法而已,本质上没有功能上的突破。
1 2 3 // Java Lambda Wrapper wrapper2 = param -> param * 2; a(wrapper2);
var、val 在声明一个变量时,我们习惯了敲打两次变量类型,第一次用于声明变量类型,第二次用于构造函数。Kotlin 可以使用 var 让编译器自己去推断类型,Java 10 也支持了这个语法。Kotlin 中还支持 val,表示该变量一旦初始化不可改变,即 final。
1 2 3 4 var codefx = new URL("http://codefx.org"); var connection = codefx.openConnection(); var reader = new BufferedReader( new InputStreamReader(connection.getInputStream()));
这样可以少敲几个字,但更重要的是,它避免了信息冗余,而且对齐了变量名,更容易阅读。当然,这也需要付出一点代价:有些变量,比如例子当中的 connection,就无法立即知道它是什么类型的。虽说 IDE 可以辅助显示出这些变量的类型,但还是需要光标放上去或者跳转到方法定义查看返回值类型,并且在其他场景下可能就完全不行了,比如在代码评审的时候。
在 new 对象的时候使用 var 推导类型,而在接某个方法的返回值时,使用完整的类型而不是 var,可能是一个比较好的办法,便于阅读。
字符串模板 Java 中,如果要拼接复杂字符串,一般用 StringBuilder 或者 String.format 方法,但如果参数过多,也非常麻烦,参数还可能对岔了。
Kotlin 支持字符串模板,它是一段代码,会计算并将结果返回到字符串中。这块古老的糖从 shell 开始就有了,但 Java 却迟迟缺席。
1 2 3 4 5 // Java String message = String.format("您好%s,晚上好!您目前余额:%.2f元,积分:%d", "张三", 10.155, 10); // Kotlin val message = "您好${user.name},晚上好!您目前余额:${cashAmount + presentAmount}元,积分:$point"
解构 Kotlin 支持将一个对象解构为多个变量,如:
1 val (name, age) = person
这种语法叫做解构声明,解构声明一次创建多个变量,之后可以独立的使用这些变量。这种语法可以用来从一个函数返回多个值。不关心的变量,可以使用下划线 _ 代替。
多返回值 很多场景需要从一个函数中返回两件事,例如,一个状态和一个结果对象。在 Java 中,一般封装成一个对象,或手写 Pair 类,但出参并不好理解,一般都叫 first、second 之类。 但解构时需要正确命名数据,否则也不太好理解。
1 2 3 4 5 6 7 8 // Kotlin fun getInfo() : Pair<Int, Any> { // 不能创建任意元组,可以使用内置的数据类型,如 Pair 和 Triple,也可自定义 return Pair(200, Any()) } // 调用 val (status, data) = getInfo()
解构声明和映射 1 2 3 4 5 6 7 8 9 // for 遍历时,解构声明 Map 中的 Entry 对象 for ((key, value) in map) { // do something with the key and the value } // lambdas 中的解构 map.mapValues { entry -> "${entry.value}!" } // 未使用的 key 可以用 _ 代替 map.mapValues { (_, value) -> "$value!" }
嵌套函数(本地函数) 在一个复杂方法中,常常会有一些相似逻辑,常规思路就是抽成一个私有方法,有时候作用域还是太大。Kotlin 支持在函数中定义作用域更小局部函数,这点类似于 JavaScript。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 fun login(user: String, password: String, illegalStr: String) { // 验证 user 是否为空 if (user.isEmpty()) { throw IllegalArgumentException(illegalStr) } // 验证 password 是否为空 if (password.isEmpty()) { throw IllegalArgumentException(illegalStr) } } fun login(user: String, password: String, illegalStr: String) { // 嵌套函数中可以访问在它外部的所有变量或常量,因此不再需要传参 illegalStr fun validate(value: String) { if (value.isEmpty()) { throw IllegalArgumentException(illegalStr) } } validate(user, illegalStr) validate(password, illegalStr) } // 其实还有更简单的方法,使用内置的 require 方法和 lambda 表达式 fun login(user: String, password: String, illegalStr: String) { require(user.isNotEmpty()) { illegalStr } require(password.isNotEmpty()) { illegalStr } }
数据类 从此告别繁琐的 Java 数据类,会自动生成 toString、hashcode、equals、getter、setter、copy 等方法,再也不需要 lombok 了。
1 data class User(val name: String, val age: Int)
但数据类的坑或者用起来不舒服的地方也较多:
它只有全参构造函数,而一些序列化框架依赖于无参构造函数,此时会出现问题。而且 new 一个数据类的时候就要把所有入参一口气设置好。
Json 字符串可能出现一些字段缺失或者 null,如果数据类的定义字段都不可空,那么序列化报错,怎么办?
所有字段都加上 ?,可空,那以后所有这个字段的使用都要加上 ?. 也是非常麻烦的,或者再加一个数据类转换一下。
约束好上游,做好定义,哪些不能为空等。
单例对象 这应该是来自于Scala,连关键字都一模一样。
别名 支持为包、类型指定别名。在工程中如果有两个类名一样,包不一样,则容易出错,一些代码必须要写完整的包路径,代码冗长难读。例如 @Service 注解,项目中可能有两个包,一个是org.springframework.stereotype.Service; ,一个是 com.dianping.pigeon.remoting.provider.config.annotation.Service; 每次都需要查看一下 import 的是哪个包,易误导人。
1 2 3 4 5 6 // 包别名,Python、Groovy 都这个语法 import org.springframework.stereotype.Service as SpringService import com.dianping.pigeon.remoting.provider.config.annotation.Service as PigeonService // 类型别名,可以一些复杂的类型设置一个别名。 和 Scala 相似,Scala 关键字为 type。 typealias Table = Map<Int, Map<String, Int>>
运算符重载 这个是 C# 和 Scala 的把戏。
1 2 3 data class Point(val x: Int, val y: Int) operator fun Point.plus(val point: Point) = Point(x + point.x, y + point.y) Point(1, 2) + Point(3, 4) // Point(x=4, y=6)
没有受检查异常 Kotlin 并没有受检查异常。因为在大型的项目中,它对代码质量的提升极其有限,但是却大大降低了效率。这个灵感大概来源于 C#,可以参考 Why doesn’t C# have checked exceptions?
集合字面量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 // Java 不愿用糖来吸引小朋友,想快速创建一个带有初始值的集合都比较麻烦 // 1. 最啰嗦的办法,无法使用单个表达式来完成 List<String> colors = new ArrayLis<>(); list.add("red"); list.add("blue"); // 2. 但这样创建出来的 ArrayList 非彼 java.util.ArrayList ,只是个内部类,没有实现 add remove 等方法 List<String> colors = Arrays.asList("red", "blue"); // 3. 使用 Stream List<String> colors = Stream.of("red", "blue").collect(Collectors.toList()); // 4. 用第三方的轮子 Guava List<String> colors = ImmutableList.of("red", "blue"); // Kotlin 集合字面量 http://openjdk.java.net/jeps/269 val list = listOf("red", "blue") val set = setOf("red", "blue") val map = mapOf("red" to "1", "blue" to "2")
when Kotlin 提供了非常强大的 when 操作符,是增强版 switch。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 //Kotlin when (x) { 1 -> print("x == 1") 2,3 -> print("x == 2 || x ==3") parseInt(s) -> print("s encodes x") // 可以使用任意表达式作为分支条件,Java 仅仅支持常量 else -> { // 每个 when 表达式都必须要有这个块 print("x is neither 1 nor 2") } } // 支持任意类型的值(调用 equals 方法进行判断), Java 只支持一些基本类型 char, byte, short, int, Character, Byte, Short, Integer, String, or an enum // 由于智能转换,在类型判断后,也无需再次转换 fun hasPrefix(x: Any) = when(x) { is String -> x.startsWith("prefix") else -> false } // 还可以无参,用来取代 if-else if链,一直判断直到匹配到一个分支 when { x.isOdd() -> print("x is odd") y.isEven() -> print("y is even") else -> print("x+y is odd.") }
其他
最后也发现了一个有趣的网站,大家也可以自己再看下。 https://www.kotlinvsjava.com
文章参考: